

-
前几天的召开的2019年大数据生态产业大会不知道大家关注到没有,看到消息是hanlp2.0版本发布了。不知道hanlp2.0版本又将带来哪些新的变化?准备近期看能够拿到一些hanlp2.0的资料,如果能顺利拿到的话,到时候分享给大家!今天分享这篇是关于将hanlp封装到web s... 全文
2019-08-09 10:03 来自版块 - 网络技术
-
深耕核心技术·赋能数字化转型 图1:2019(第四届)大数据产业生态大会8月1日,以“激活数据价值 释放数据原力”为主题的“2019(第四届)大数据产业生态大会”在北京拉开序幕。北京大学教授、工业和信息化部原副部长杨学山,工业和信息化部信息化... 全文

2019-08-07 16:53 来自版块 - 网络技术
-
本篇分享一个hanlp分词工具应用的案例,简单来说就是做一图库,让商家轻松方便的配置商品的图片,最好是可以一键完成配置的。先看一下效果图吧:
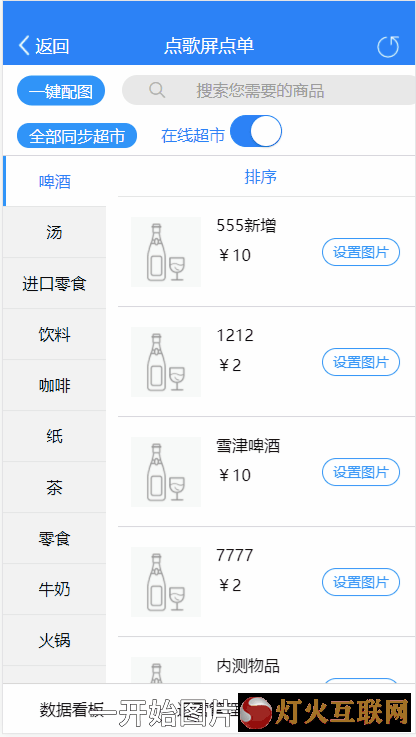
2019-08-07 11:43 来自版块 - 网络技术
-
本篇文章将重点讲解HanLP的ViterbiSegment分词器类,而不涉及感知机和条件随机场分词器,也不涉及基于字的分词器。因为这些分词器都不是我们在实践中常用的,而且ViterbiSegment也是作者直接封装到HanLP类中的分词器,作者也推荐使用该分词器,同时文本分类包以... 全文
2019-08-05 10:31 来自版块 - 网络技术
-
HanLP发射矩阵词典nr.txt中收录单字姓氏393个。袁义达在《中国的三大姓氏是如何统计出来的》文献中指出:当代中国100个常见姓氏中,集中了全国人口的87%,根据这一数据我们只保留nr.txt中的100个常见词语的姓氏角色,其他词语去掉其姓氏角色状态。过滤后,nr.txt中... 全文
2019-08-02 10:00 来自版块 - 网络技术
-
人名识别在HanLP中,基于角色标注识别了中国人名。首先系统利用隐马尔可夫模型标注每个词语的角色,之后利用最大模式匹配法对角色序列进行匹配,匹配上模式的即为人名。理论指导文章为:《基于角色标注的中国人名自动识别研究》,大家可以百度一下看看地名识别 理论指导文章为:《基于层叠隐马尔... 全文
2019-07-31 13:08 来自版块 - 网络技术
-
HanLP收词特别是实体比较多,因此特别容易造成误识别。下边举几个地名误识别的例子,需要指出的是,后边的机构名识别也以地名识别为基础,因此,如果地名识别不准确,也会导致机构名识别不准确。 全文
2019-07-29 10:54 来自版块 - 网络技术
-
本篇接上一篇内容《HanLP-基于HMM-Viterbi的人名识别原理介绍》介绍一下层叠隐马的原理。首先说一下上一篇介绍的人名识别效果对比:1. 只有Jieba识别出的人名准确率极低,基本为地名或复杂地名组成部分或复杂机构名组成部分。举例如下:[1] 战乱的阿富汗地区,qiang... 全文
2019-07-26 09:51 来自版块 - 网络技术
-
Hanlp自然语言处理包中的基于HMM-Viterbi处理人名识别的内容大概在年初的有分享过这类的文章,时间稍微久了一点,有点忘记了。看了 baiziyu 分享的这篇比我之前分享的要简单明了的多。下面就把文章分享给大家交流学习之用,部分内容有做修改。 全文
2019-07-24 10:23 来自版块 - 网络技术
2019-07-22 10:02 来自版块 - 网络技术
-
HanLP收词特别是实体比较多,因此特别容易造成误识别。下边举几个地名误识别的例子,需要指出的是,后边的机构名识别也以地名识别为基础,因此,如果地名识别不准确,也会导致机构名识别不准确。 类型1 数字+地名[1] 暗访哈尔滨网约车:下10单来7辆“黑车” 1辆套牌[2] 房天下每... 全文
2019-07-19 10:42 来自版块 - 网络技术
-
Python调用hanlp的方法此前有分享过,本篇文章分享自“逍遥自在017”的博客,个别处有修改,阅读时请注意!1.首先安装jpype首先各种坑,jdk和python 版本位数必须一致,我用的是JPype1-py3 版本号0.5.5.2 、1.6jdk和Python3.5,wi... 全文
2019-07-17 10:26 来自版块 - 网络技术
-
本文分享自 6丁一的猫 的博客,主要是python调用hanlp进行命名实体识别的方法介绍。以下为分享的全文。1、python与jdk版本位数一致 2、pip install jpype1(python3.5) 3、类库hanlp.jar包、模型data包、配置文件hanlp.... 全文
2019-07-15 09:57 来自版块 - 网络技术
-
本篇分享一个hanlp添加自定义字典的方法,供大家参考!总共分为两步:第一步:将自定义的字典放到custom目录下,然后删除CustomDicionary.txt.bin,因为分词的时候会读这个文件。如果没有的话它会根据配置文件中路径去加载字典生成bin文件。 全文
2019-07-12 10:22 来自版块 - 网络技术
-
项目简要:关于java web的一个项目,用的Spring MVCd 框架。鉴于参与此次项目的人中并不是所人都做的Spring,为了能够提高效率,建议大家是先抛开SPring来写自己负责的模块,最后再把各个模块在Spring里面集成。项目里有一个文本分析的模块是一个同学用hanl... 全文
2019-07-10 10:29 来自版块 - 网络技术
-
前几天(6月28日),在第23届中国国际软件博览会上,hanlp这款自然语言处理工具荣获了“2019年第二十三届中国国际软件博览会优秀产品”。HanLP是由一... 全文

2019-07-03 10:51 来自版块 - 网络技术
-
摘要:elasticsearch是使用比较广泛的分布式搜索引擎,es提供了一个的单字分词工具,还有一个分词插件ik使用比较广泛,hanlp是一个自然语言处理包,能更好的根据上下文的语义,人名,地名,组织机构名等来切分词Elasticsearch默认分词 全文

2019-07-01 11:24 来自版块 - 网络技术
-
繁简转换HanLP几乎实现了所有我们需要的繁简转换方式,并且已经封装到了HanLP中,使得我们可以轻松的使用,而分词器中已经默认支持多种繁简格式或者混合。这里我们不再做过多描述。 ·说明· HanLP能够识别简繁分歧词,比如打印机=印表機。许多简繁转换工具不能区分“以后”“皇后”... 全文
2019-06-28 10:06 来自版块 - 网络技术
-
基于字标注法的分词中文分词字标注通常有2-tag,4-tag和6-tag这几种方法,其中4-tag方法最为常用。标注集是依据汉字(其中也有少量的非汉字字符)在汉语词中的位置设计的。1. 2-tag法 2-tag是一种最简单的标注方法,标注集合为{B,I},其将词首标记设计为B,而... 全文
2019-06-26 10:52 来自版块 - 网络技术
-
中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,不同于英文的是,中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词,分词效果将直接影响词性,句法树等模块的效果,当然分词只是一个工具,场景不同,要求也不同。在人机自然语言交互中,成熟的... 全文
2019-06-24 10:37 来自版块 - 网络技术
