

-
问题因为需要加载一个 近 1G 的字典到Hanlp中,一开始使用了CustomDictionay.add() 方法来一条条的加载,果然到了中间,维护DoubleArraTre 的成本太高,添加一个节点,都会很长时间,本来时间长一点没有关系,只要训练出.bin 的文件,... 全文

2019-01-23 10:26 来自版块 - 网络技术
-
本篇分享一个使用hanlp分词的操作小案例,即在spark集群中使用hanlp完成分布式分词的操作,文章整理自【qq_33872191】的博客,感谢分享!以下为全文: 分两步:第一步:实现hankcs.hanlp/corpus.io.IIOAdapter 全文
2019-01-21 10:37 来自版块 - 网络技术
-
此文整理的基础是建立在hanlp较早版本的基础上的,虽然hanlp的最新1.7版本已经发布,但对于入门来说差别不大!分享一篇比较早的“旧文”给需要的朋友!安装HanLPHanLP将数据与程序分离,给予用户自定义的自由。 HanLP由三部分组成:HanLP = .jar ... 全文

2019-01-18 11:29 来自版块 - 网络技术
-
Hadoop作为搭建大数据处理平台的重要“基石”,关于它的分析和讲解的文章已经有很多了。Hadoop本身是一分布式的系统,因此在安装的时候,需要多每一个节点进行组建的安装。并且由于是开源软件,其安装过程相对比较复杂。这也是很多人在搭建hadoop运行环境时总是不能一次性成功的主要... 全文
2019-01-16 16:12 来自版块 - 网络技术
-
这是一个基于CRF的中文依存句法分析器,内部CRF模型的特征函数采用 双数组Trie树(DoubleArrayTrie)储存,解码采用特化的维特比后向算法。相较于《最大熵依存句法分析器的实现》,分析速度翻了一倍,达到了1262.8655 sent/s开源项目本文代码已集成到Han... 全文
2019-01-16 13:45 来自版块 - 网络技术
-
在上一篇的文章中已经明确说过DKM作为大快发行版DKhadoop的管理平台,它的四大功能分别是:管理功能,监控功能,诊断功能和集成功能。管理功能已经给大家列举了一些做了说明,今天就DKM平台的监控功能再给大家做细致的分享分析。 全文

2019-01-14 15:12 来自版块 - 网络技术
-
最近高产似母猪,写了个基于AP的中文分词器,在Bakeoff-05的MSR语料上F值有96.11%。最重要的是,只训练了5个迭代;包含语料加载等IO操作在内,整个训练一共才花费23秒。应用裁剪算法去掉模型中80%的特征后,F值才下降不到0.1个百分点,体积控制在11兆。如果训练一... 全文
2019-01-14 10:59 来自版块 - 网络技术
-
之前几周的时间一直是在围绕DKhadoop的运行环境搭建写分享,有一些朋友留言索要了dkhadoop安装包,不知道有没有去下载安装一探究竟。关于DKHadoop下载安装基本已经讲清楚了,这几天有点空闲把大快DKM大数据运维管理平台的内容整理了一些,作为DKHadoop相配套的管理... 全文
2019-01-11 15:24 来自版块 - 网络技术
-
HanLP分词命名实体提取详解分享一篇大神的关于hanlp分词命名实体提取的经验文章,文章中分享的内容略有一段时间(使用的hanlp版本比较老),最新一版的hanlp已经出来了,也可以去看看新版的hanlp在这方面有何提升!文本挖掘是抽取有效、新颖、有... 全文

2019-01-11 14:14 来自版块 - 网络技术
-
关于hadoop的分享此前一直都是零零散散的想到什么就写什么,整体写的比较乱吧。最近可能还算好的吧,毕竟花了两周的时间详细的写完的了hadoop从规划到环境安装配置等全部内容。写过程不是很难,最烦的可能还是要给每一步配图,工程量确实比较大。原计划准备接上一篇内容写dkhadoop... 全文
2019-01-09 15:32 来自版块 - 网络技术
-
HanLP极致简繁转换详细讲解作者: hankcs(大快高级研究员 hanlp项目负责人)谈起简繁转换,许多人以为是小意思,按字转换就行了。事实上,汉语历史悠久,地域复杂,发展至今在字符级别存在“一简对多繁”和“一繁对多简”,在词语级别上存在“简繁分歧词”,在港澳台等地则存在“字... 全文
2019-01-09 13:17 来自版块 - 网络技术
-
前两天看到有人留言问在什么情况下需要部署hadoop,我给的回答也很简单,就是在需要处理海量数据的时候才需要考虑部署hadoop。关于这个问题在很早之前的一篇分享文档也有说到这个问题,数据量少的完全发挥不了hadoop的优势,所以也没必要部署。但对于正在学习hadoop的朋友来说... 全文
2019-01-07 15:16 来自版块 - 网络技术
-
pyhanlp实现的分词器有很多,同时pyhanlp获取hanlp中分词器也有两种方式第一种是直接从封装好的hanlp类中获取,这种获取方式一共可以获取五种分词器,而现在默认的就是第一种维特比分词器1.维特比 (viterbi):效率和效果的最佳平衡。也是最短路分词,HanLP... 全文
2019-01-07 13:12 来自版块 - 网络技术
-
Hadoop分布式集群环境搭建是每个入门级新手都非常头疼的事情,因为你可能花费了很久的时间在搭建运行环境,最终却不知道什么原因无法创建成功。但对新手来说,运行环境搭建不成功的概率还蛮高的。在之前的分享文章中给hadoop新手入门推荐的大快搜索DKHadoop发行版,在运行环境安装... 全文
2019-01-04 14:31 来自版块 - 网络技术
-
简介HanLP中的词语提取是基于互信息与信息熵。想要计算互信息与信息熵有限要做的是 文本分词进行共性分析。在作者的原文中,有几个问题,为了便于说明,这里首先给出短语提取的原理。在文末在给出pyhanlp的调用代码。共性分析 全文
2019-01-04 10:40 来自版块 - 网络技术
-
自然语言处理定义:自然语言处理是一门计算机科学、人工智能以及语言学的交叉学科。虽然语言只是人工智能的一部分(人工智能还包括计算机视觉等),但它是非常独特的一部分。这个星球上有许多生物拥有超过人类的视觉系统,但只有人类才拥有这么高级的语言。自然语言处理的目标是让计算机处理或说“理解... 全文
2019-01-02 14:31 来自版块 - 网络技术
-
【环境】python 2.7 方法一:使用pyhanlp,具体方法如下:pip install pyhanlp # 安装pyhanlp进入python安装包路径,如/usr/lib/python2.7/site-packages/pyhanlp/static/将http... 全文

2019-01-02 11:00 来自版块 - 网络技术
-
Hadoop对于从事互联网工作的朋友来说已经非常熟悉了,相信在我们身边有很多人正在转行从事hadoop开发的工作,理所当然也会有很多hadoop入门新手。Hadoop开发太过底层,技术难度远比我们想象的要大,对新手而言选择一个合适的hadoop版本就意味着上手更快!Hadoop是... 全文
2018-12-28 16:09 来自版块 - 网络技术
-
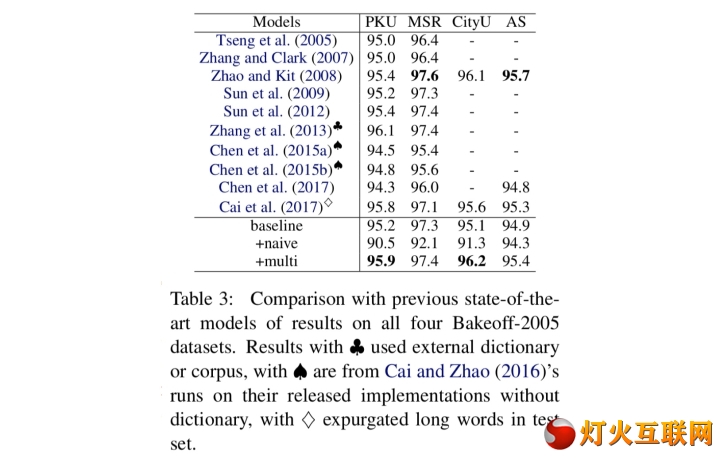
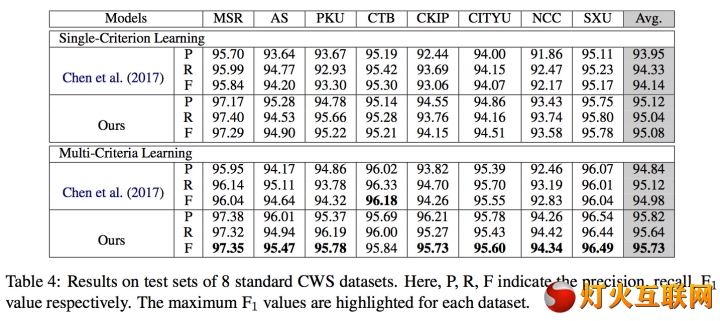
本文介绍一种简洁优雅的多标准中文分词方案,可联合多个不同标准的语料库训练单个模型,同时输出多标准的分词结果。通过不同语料库之间的迁移学习提升模型的性能,在10个语料库上的联合试验结果优于绝大部分单独训练的模型。模型参数和超参数全部共享,复杂度不随语料库种类增长。(相关内容已经集成... 全文
2018-12-28 15:16 来自版块 - 网络技术
-
大数据这个词也许几年前你听着还会觉得陌生,但我相信你现在听到hadoop这个词的时候你应该都会觉得“熟悉”!越来越发现身边从事hadoop开发或者是正在学习hadoop的人变多了。作为一个hadoop入门级的新手,你会觉得哪些地方很难呢?运行环境的搭建恐怕就已经足够让新手头疼。如... 全文
2018-12-26 15:03 来自版块 - 网络技术
